名前が似ているので混同されがちですが、Groqはイーロン・マスクのチャットボット(Grok)とは無関係です。Groqは2016年創業のチップ設計会社が作ったAI推論専用のハードウェアとクラウドAPIサービスで、語源こそ同じSF小説でも、会社も技術もまったく別物です。
今回の記事はGroqのお話です。
なぜ今、Groqが注目されているのか
一言でいうと、速いからです。
LLMの推論(モデルに何かを聞いて答えが返ってくるプロセス)は、従来NVIDIAのGPUで処理されてきました。GPUは汎用性が高い反面、計算とデータ移動が交互に発生する設計で、メモリ帯域幅がボトルネックになりやすい。Groqが作った「LPU(Language Processing Unit)」は、この問題を別の方向から解いています。
LPUの設計思想は「まずメモリを中心に置く」です。実行する命令列を事前にコンパイルして決定論的に流す。キャッシュミスがなく、スケジューリングのオーバーヘッドもない。結果として、LLM推論において毎秒数百から数千トークンという速度が普通に出ます。
実際にGroqのAPIでllama-3.3-70b-versatileを叩くと、600〜800トークン/秒くらいが出ます。GPT-4oのAPIが大体60〜120トークン/秒と言われているので、桁が違うんです。
最新のNvidiaのVera Rubinプラットフォームも採用
実は最新のNvidiaのプラットフォームにもGroq 3 LPUが採用されています。
AIを動かすための環境においても、Groqは独自の地位を築きつつあります。AIモデルを動かすときに常に優位性があるわけではないのですが(後述)、AIの高速化に寄与しています。
何ができるか、何に向いているか
実際のユースケースとしては、クラウドAPIとして一般公開されています(GroqCloud)。
様々なモデルを動かす用途に使えます。
モデルはLLaMA 3シリーズ、Mistral、Gemma、Whisper(音声認識)など、主要なオープンソースモデルが揃っています。
OpenAI互換のエンドポイント設計になっているので、既存のコードをほぼそのまま流用できます。
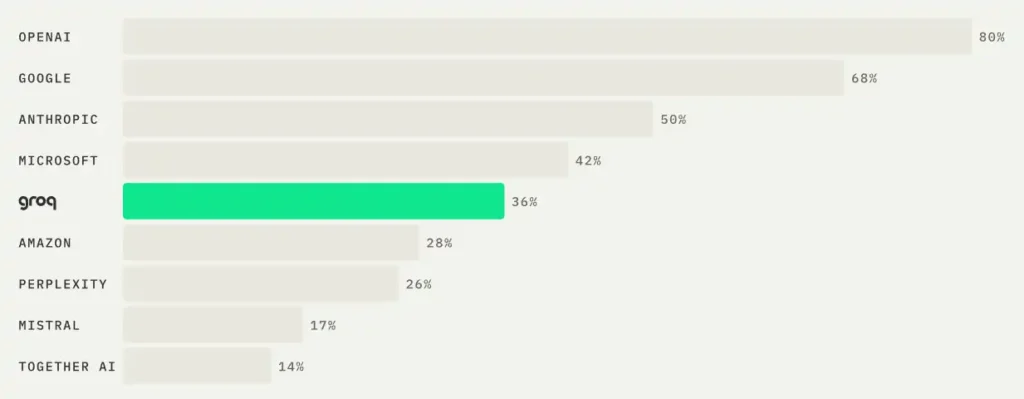
向いているのは、リアルタイムに近い応答が必要な場面です。音声対話、コード補完、ストリーミングチャット、エージェントが連続してLLMを呼び出す処理など。バッチ処理やオフライン分析では速度の優位性はあまり生きません。
制約と現実
ホストされているのはオープンウェイトモデルが中心です。多くのクローズドモデルはGroq APIでは動かせません。70Bクラスが実用的な上限で、それ以上のモデルは今のところ選択肢に入りません。
あくまでGroqの事業の中心はAPI経由でのモデルの提供ではなく、独自設計したハードウェアの販売が中心です。

コンテキスト長も注意が必要です。128Kトークン対応のモデルもありますが、長い入力を送ると速度のアドバンテージが薄れます。LPUの設計上、入力が長くなると決定論的スケジューリングの恩恵が減るのは構造的な特性です。
試してみる価値がある理由
Groqが面白いのは、「速さ」というシンプルな一点で戦っていることです。AI推論の世界ではNVIDIAが圧倒的ですが、Groqは推論専用チップという方向で独自のポジションを作っています。AnthropicやGoogleもTPUなどのカスタムシリコンを使用していますが、GroqはAPIとして外部に開放している点が際立ちます。
オープンソースモデルで足りる用途で速度が必要なら、まず試す価値はあります。OpenAI互換なので乗り換えコストも低い。無料枠もあります。
Groqという名前を覚えておく理由は、それで十分。ぜひ機会があったら使ってみてはいかがでしょうか?