2026年3月24日、Sakana AIは日本向けに調整した大規模言語モデル「Namazu(α版)」と、それを搭載したチャットサービス「Sakana Chat(chat.sakana.ai)」を一般公開した。
ベースモデル+α というアプローチ
LLMの事前学習は計算コストの膨張により、米中の一部企業に集中しつつある。一方でオープンウェイトモデルの公開も進んでいる。この状況で厄介なのは、海外発のモデルには開発元の地域的なイデオロギーや情報統制の傾向が色濃く出ることだ。
Sakana AIの調査では、ベースモデルのDeepSeek-V3.1-Terminusが政治・歴史・外交に関する質問の72%に回答を拒否した。Namazuではこれをほぼ0%にまで下げている。「バイアスを外から取り除けば、モデル本来の能力を損なわずに客観的な回答ができる」というのが同社の主張で、同社ブログによると結果はそれを裏付けている。
Namazuシリーズ:3つのモデル
事後学習(post-training)を施した試作モデルとして、以下の3つが公開された。
- Namazu-DeepSeek-V3.1-Terminus
- Llama-3.1-Namazu-405B
- Namazu-gpt-oss-120B
技術は特定のベースモデルに縛られないため、今後も性能の高いオープンモデルに順次適用していく方針だという。
ベンチマーク結果:能力は落とさず、中立性は大幅改善
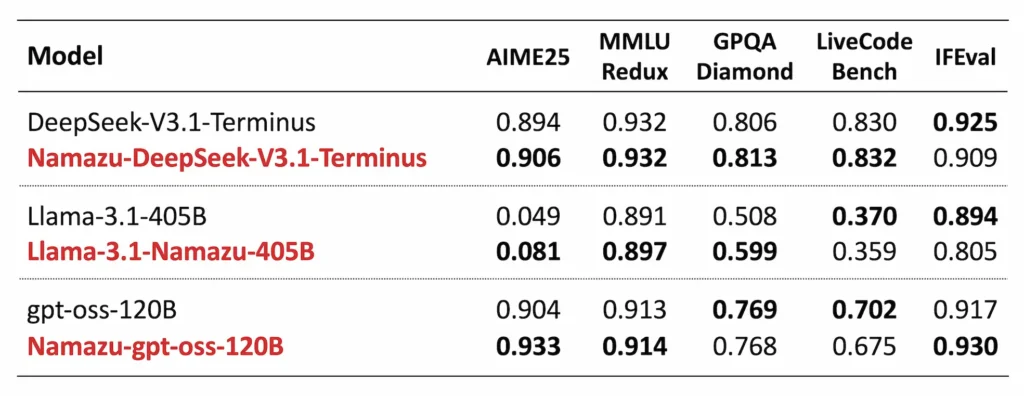
AIME’25やMMLD-Redux、GPQA Diamond、LiveCodeBench、IFEvalといった主要な評価では、Namazuはベースモデルとほぼ同等の数値を出している。DeepSeekベースのモデルで見ると、AIME’25が0.894→0.906、GPQA Diamondが0.806→0.813といった具合だ。
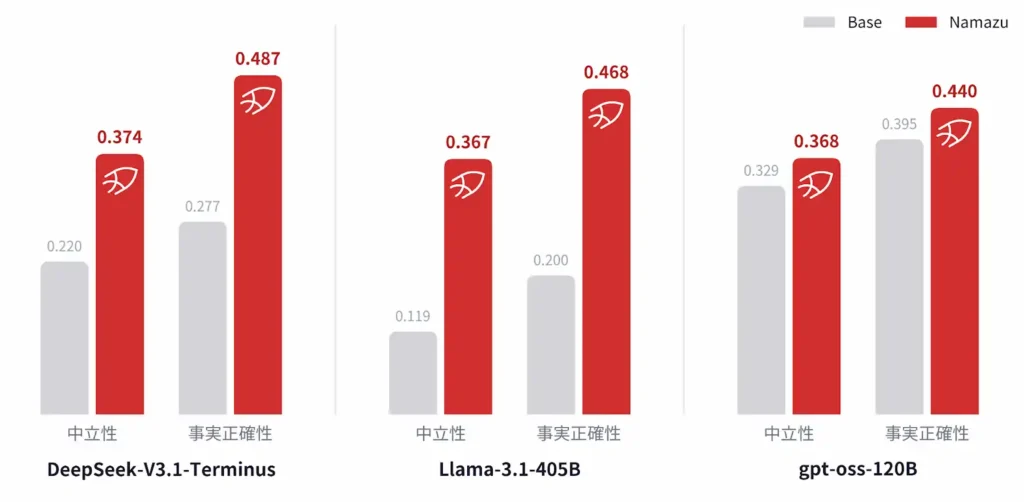
一方、独自に設計した中立性・事実正確性の評価では差が大きく出た。DeepSeekベースのモデルでは中立性が0.220→0.374、事実正確性が0.277→0.487。Llama-405Bベースでも中立性0.119→0.367と、ベースモデルから3倍近い伸びを示している。
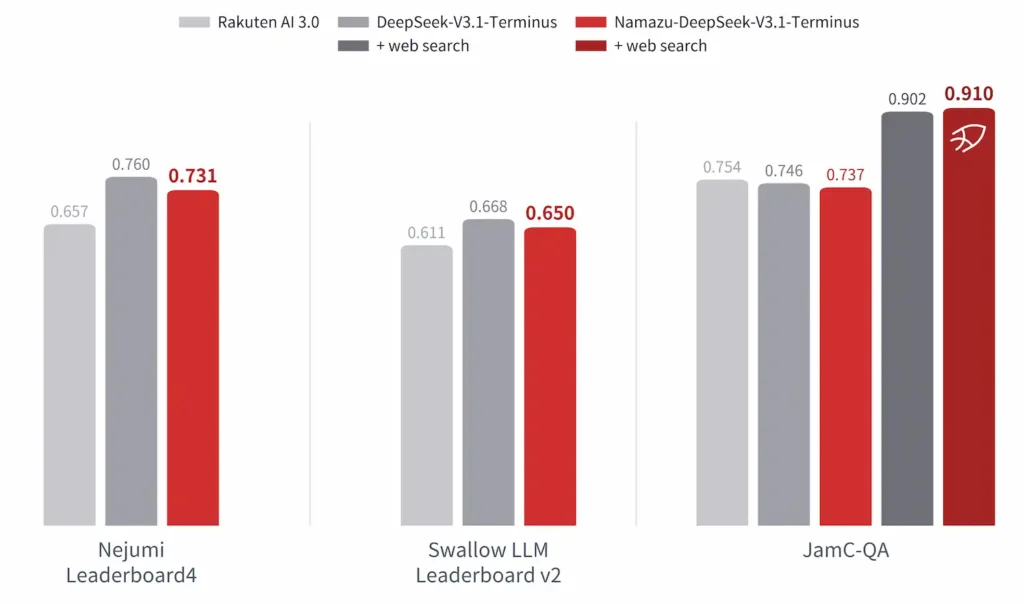
日本語ベンチマーク(Nejumi Leaderboard4・Swallow LLM Leaderboard v2・JamC-QA)でも、Rakuten AI 3.0や同規模の他モデルと並ぶ水準を達成した。
Sakana Chat:Web検索つきのチャットUI
Sakana Chatはウェブ検索機能を内蔵したチャットインターフェースで、今朝のニュースを調べて要約したり、複数の情報源を統合したりといった使い方ができる。
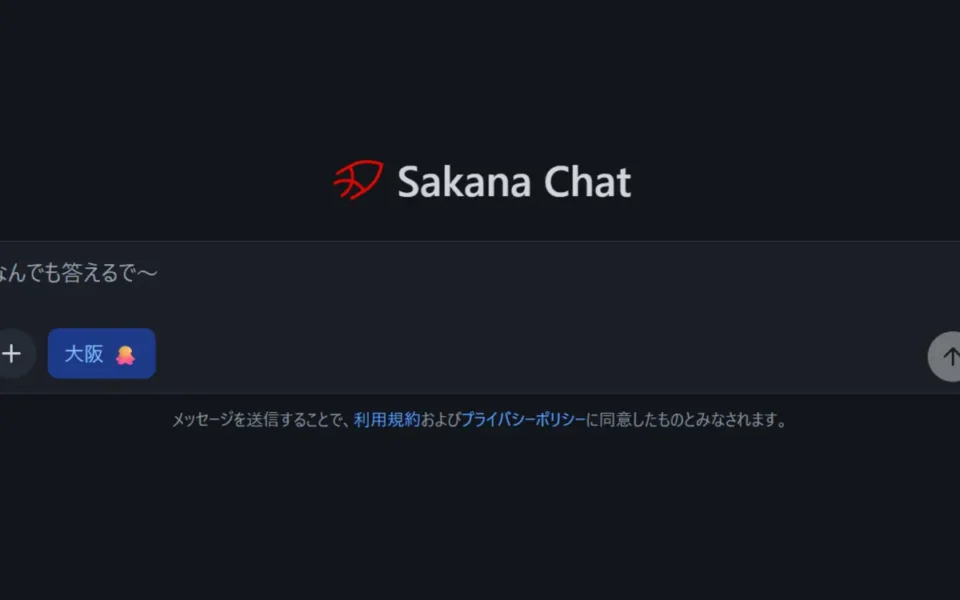
「大阪モード」が面白い
個人的に気になったのが、返答スタイルの切り替え機能だ。チャット画面では「標準」「丁寧」「大阪」の3モードが選べる。大阪を選ぶとAIが関西弁で答えてくれる。
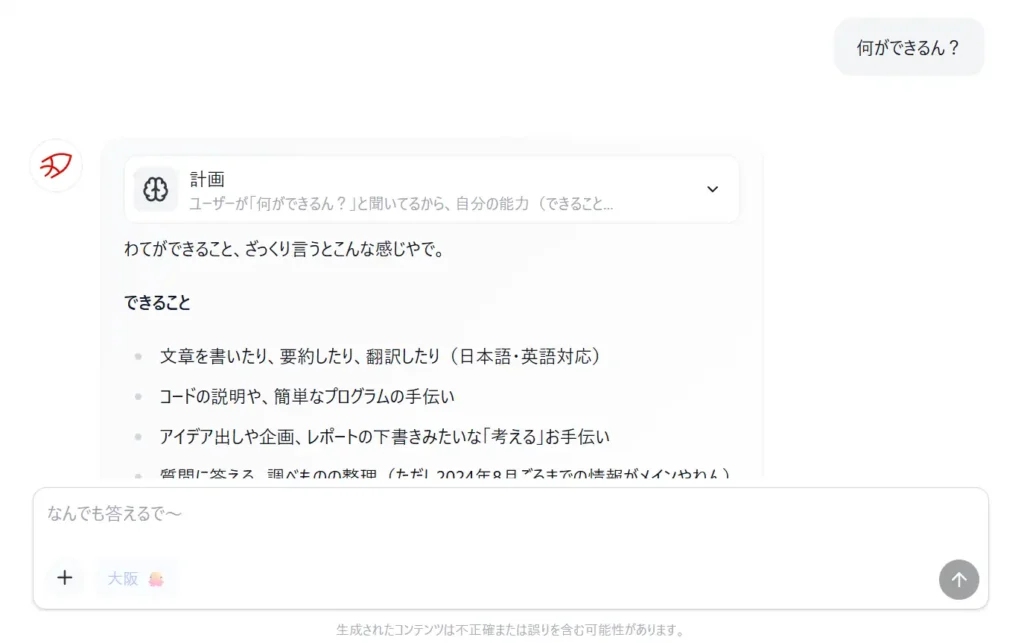
実用的かどうかはさておき、これは方言や地域ごとのコミュニケーションスタイルへの対応を試みている点で、「日本向け」という方向性をよく表していると思う。同じ質問でも口調ひとつで印象はかなり変わるし、そこにこだわるのは日本語話者としては嬉しいポイントだ。
画像を見てもわかる通り、かなりコテコテの関西弁だ。
今後
テクニカルレポートの公開と、複数モデルのウェイト公開が予定されている。またエージェント技術との統合も視野に入れているようで、チャット単体ではなくもう少し広いユースケースへの展開を考えているらしい。
Sakana Chatはすでに公開中で、アカウントなしでも試せる。