Google が Gemma 4 を公開した。E2B・E4B・26B-A4B(MoE)・31B の4サイズの展開だ。
ライセンスは Apache 2.0 に変わった。以前は独自のライセンス(Gemma Terms of Use)を採用していた点を考えると、よりオープンになった形だ。
気になる性能から
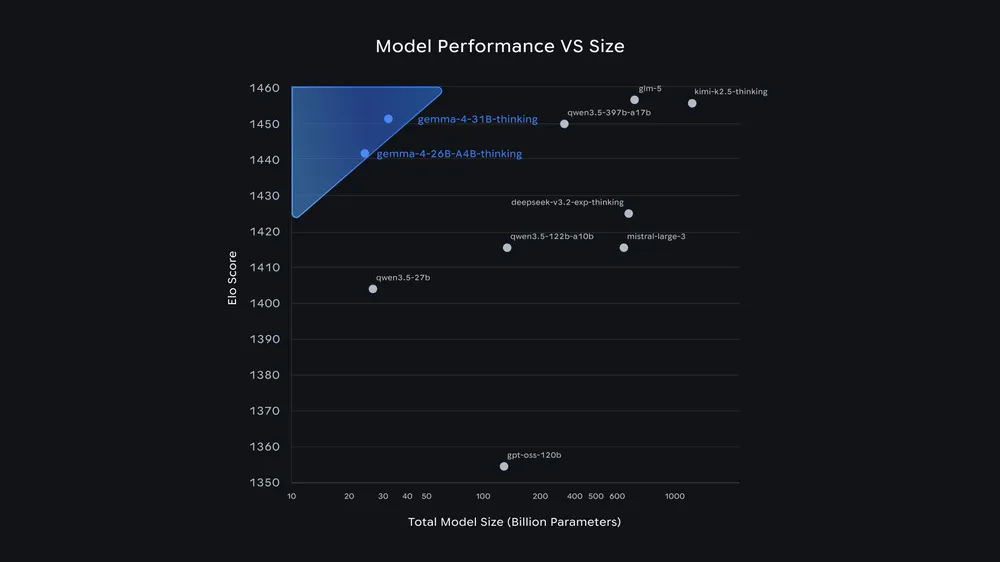
ベンチマークから入ると、Arena.ai のチャットアリーナで 31B はオープンモデルで3位、26Bモデルは 6 位。添付のグラフを見れば、30B 台のモデルが 400B 超のモデルとほぼ並んでいるのがわかる。
パラメータ数だけが性能を決めるわけではないという話は今まで各社さんざん言い続けてきたことであるが、今回のスコアはそれを無視しにくい形で示している。どこまで実用タスクでも同じことが言えるかは未知数だが、全モデルのGemma 3よりもかなり性能が向上しているのは間違いなさそうだ。
多機能さが目を引く
機能で目を引くのはエージェント対応の本気度だ。ファンクションコール、構造化 JSON 出力、システムプロンプトがネイティブで動くらしい。
コンテキスト長はエッジモデルで 128K、大型モデルは 256K。全モデルが画像・動画に対応し、小型の E2B と E4B は音声入力まで対応している。140言語対応というのも、グローバル展開を前提にしたプロダクトを考えるときにGemma 4が魅力的に見えてくる数字だ。
ハードウェア要件も具体的に出ている。
31Bモデルのbf16重みはH100 80GB 1枚。量子化すればコンシューマGPUでも動く。E2B・E4BはRaspberry Pi やJetson Orin Nanoでのオフライン推論を想定しており、Android の AICore開発者プレビューへも対応している。スマートフォン上での実用がどこまでいくかは、端末側の制約との綱引きになる部分が多いが、スマートフォンでのエッジAIが性能的にも現実的になっている。
寛大なライセンス
これまでのGemmaは独自の利用規約が適用されており、商用利用には条件がついていた。具体的には、月間アクティブユーザーが一定数を超える場合は Googleへの事前申請が必要で、大規模なプロダクト展開をしようとすると手続きのハードルが生じていた。Apache 2.0 にはそういった制限がない。使って、改変して、配布して、商用製品に組み込む。それが基本的に自由にできるわけだ。
Hugging Face、vLLM、llama.cpp、Ollama といったツールが初日からサポートを出している点は、このライセンス変更と無関係ではないだろう。オープンモデルのエコシステムは Apache 2.0 や MIT を前提に動いていることが多く、独自規約のモデルはツール側がサポートに慎重になるケースがある。今回の変更で、その摩擦がなくなった。企業が自社インフラに乗せて使う際も、法務確認のコストが下がる。
モデルの性能と並んで、ここが実際の採用率に効いてくる部分になりそうだ。
実用面での評価はこれからだが、結果は数週間のうちに出そろってくるはずだ。楽しみにしておきたい。