2026年3月17日、楽天グループ株式会社は、経済産業省およびNEDO(新エネルギー・産業技術総合開発機構)が推進する生成AI開発力強化プロジェクト「GENIAC(Generative AI Accelerator Challenge)」の一環として開発した、国内最大規模の最新AIモデル「Rakuten AI 3.0」の提供を開始した。
約7,000億(700B)パラメータのMoEアーキテクチャを採用
本モデルは日本語に最適化された約7,000億パラメータのMixture of Experts(MoE)アーキテクチャを採用している。文章作成、コード生成、文書解析・抽出など幅広いテキスト処理用途に対応しており、従来の楽天製モデルと比較して、特に複雑なタスクへの対応精度が大幅に向上した。なお、楽天がこれまでに開発してきたモデルは「Rakuten AI 7B」(約70億パラメータ)、「Rakuten AI 2.0」(約470億パラメータ)であり、今回の3.0は規模の面でも大きな飛躍を遂げた。
性能面では複数の日本語ベンチマークにおいて優れた結果を示している。日本固有の文化・歴史知識QAを評価する「JamC-QA」では76.9点、大学院レベルの推論タスク「MMLU-ProX(日本語)」では71.7点を記録し、OpenAIの「gpt-4o」(それぞれ74.7点、64.9点)を上回るスコアを達成した。競技レベルの数学問題を扱う「MATH-100(日本語)」でも86.9点と突出した数値を叩き出している。
Rakuten AI 3.0 (LLM) と主要なモデルの比較
| モデル名 | JamC-QAスコア(注4) | MMLU-ProX(日本語)スコア(注5) | MATH-100(日本語)スコア(注6) | M-IFEval(日本語)スコア(注7) |
| Rakuten AI 3.0 | 76.9 | 71.7 | 86.9 | 72.1 |
| gpt-4o | 74.7 | 64.9 | 75.8 | 67.3 |
| GPT-OSS-Swallow-120B-RL-v0.1 | 63.0 | 63.0 | 70.5 | 69.5 |
| Stockmark-2-100B-Instruct | 61.1 | 41.7 | 55.6 | 45.6 |
| ABEJA-QwQ32b-Reasoning-v1.0 | 61.1 | 61.1 | 52.7 | 61.9 |
比較表でGPT-OSS-Swallowが謎の低スコア
この比較表で見逃せないのが、東京科学大Swallowチームが開発した「GPT-OSS-Swallow-120B-RL-v0.1」のスコアだ。楽天の発表ではJamC-QAが63.0点、MMLU-ProX(日本語)が63.0点、MATH-100が70.5点、M-IFEvalが69.5点と、Rakuten AI 3.0に対して全項目で劣後する結果となっている。
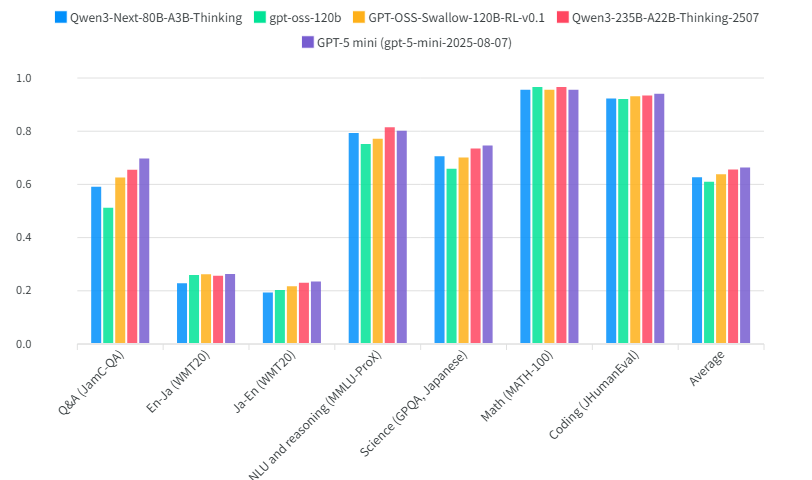
ただし、この数字をそのままGPT-OSS-Swallowの評価として受け取るには注意が必要だ。GPT-OSS-Swallowは、OpenAIが公開したgpt-oss-120bをベースに、継続事前学習・SFT・強化学習(RLVR)の三段階で日本語対応を強化したモデルだ。別の評価環境(上図)では、JamC-QAスコアはベースモデルgpt-oss-120bの約0.51から約0.63へと約12ポイント改善しており、MATH-100に至っては約0.97と楽天の評価環境(70.5点)から大幅に乖離している。
この乖離が最も顕著なのがMATH-100だ。楽天の比較表では70.5点(0.705)にとどまる一方、上図では約0.97と、同一モデルとは思えないほどの開きがある。これは評価時のプロンプト設計・few-shot数・正解判定ロジックといった条件の違いがスコアを大きく左右することを端的に示しており、今回の楽天の比較表はあくまで「楽天の評価環境における相対比較」として読むべきだ。
こうした評価条件の非統一は、日本語LLM性能比較全体に潜む構造的な問題でもある。各組織が独自の環境でスコアを報告する現状では、横断的な比較に際して「誰の物差しで測ったか」という文脈を念頭に置くことが不可欠だ。
ベースモデルはDeepSeek-V3か——OSSモデルを日本語特化で磨き上げた模様
HuggingFaceのモデルカードには、本モデルのライセンス関係先として「DeepSeek-V3」が記載されており、Apache 2.0ライセンスのもとで公開されている。あくまで推測であるが、モデルの大きさとライセンスからDeepSeek-V3に追加学習やチューニングを施したものだと考えられる。どれほどの工数をかけているのかは現時点において不明だ。
DeepSeek-V3は、671Bの総パラメータ数を持つMoE型言語モデルであり、トークンごとに37Bのパラメータを活性化する設計を採用している。14.8兆トークンの大規模データで事前学習を行い、当時の最強オープンソースベースモデルの一つとして広く知られている。
楽天はこのDeepSeek-V3をベースに、独自の高品質なバイリンガルデータと研究成果を組み合わせることで、日本語の微妙なニュアンスや文化・慣習への深い理解を実現したとしている。中国発のオープンソースモデルを「日本語特化の土台」として活用し、国産AIモデルへと仕上げるアプローチは、近年の国内AI開発における一つの有効な手法として定着しつつある。
一部の人たちがベースモデルが海外製であることを問題視しているが、学習にかけるコストを考えるといたって普通の選択であるということをここに強調しておきたい。
DeepSeekとは何か?を知りたい方には下記記事がおすすめだ。

ライセンスの細かな齟齬——Apache 2.0か、MITか
技術的に注目すべき点として、本モデルのライセンス表記に若干の曖昧さが存在する。
楽天の公式プレスリリースはモデルの配布ライセンスをApache 2.0と明記しており、HuggingFaceのモデルカード上の表示も「Apache License, Version 2.0(apache-2.0)」となっている。
一方、HuggingFaceのリポジトリには「NOTICE」ファイルが別途追加されており(コミットメッセージ: “Add the permission notice”)、そこに記載されているのはMITライセンスの条文だ(冒頭の著作権表示:「Copyright (c) 2023 DeepSeek」)。
これはベースモデルであるDeepSeek-V3の由来に関わるものとみられる。DeepSeek-V3のコードリポジトリはMITライセンスのもとで公開されているため、楽天がその条件を受け継ぐ形でNOTICEファイルを追加したものと考えられる。Apache 2.0もMITも、商用利用・改変・再配布を広く認める寛容なオープンソースライセンスであり、利用者の権利という観点では実質的な違いはほぼない。ただし、Apache 2.0には特許権の明示的な付与条項が含まれる点でMITとは構造が異なる。モデルカードの正式表記はApache 2.0だが、NOTICEファイルにMITの帰属表示が混在している状況は、今後の利用・派生開発にあたって確認しておくべき事項といえるだろう。
GENIACによる国策支援と産業界への波及
楽天は2025年7月にGENIACの第3期公募に採択されており、本モデルの学習費用の一部がGENIACの補助を受けている。経産省主導のこのプロジェクトは、日本における生成AIの自律的な開発基盤の確立を目的としており、楽天はその旗手の一つとして位置付けられている。
楽天グループのChief AI & Data Officer(CAIDO)であるティン・ツァイ氏は、「経済産業省とも連携し、日本全国の人々に変革をもたらす協調的なAI開発コミュニティを構築することを目指す」と述べており、オープンモデルとして公開することでAIアプリケーションやLLMのさらなる開発を後押しする方針を示した。
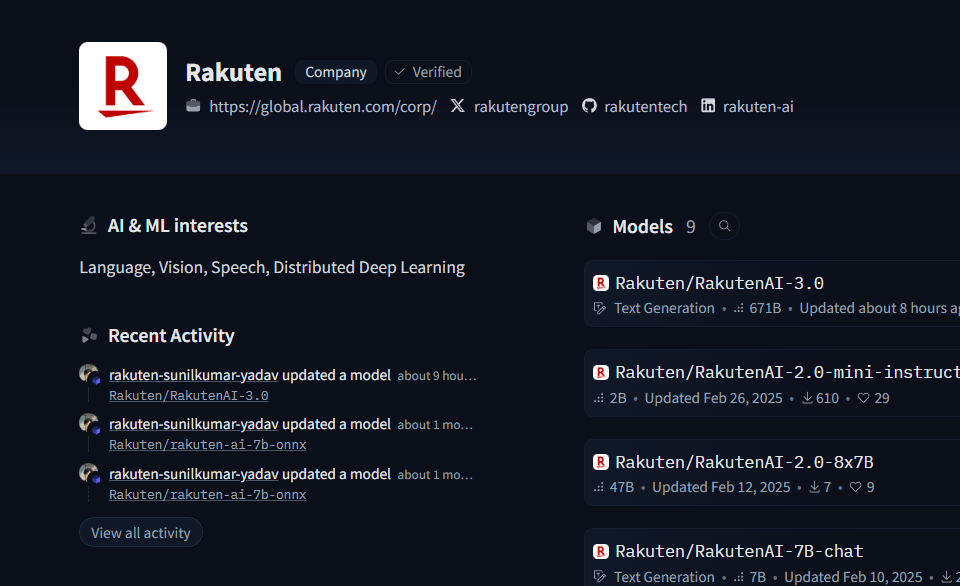
本モデルは現在、楽天グループの公式HuggingFaceリポジトリ(https://huggingface.co/Rakuten)からダウンロード可能。研究・開発用途での活用はもちろん、企業や開発者がRakuten AI 3.0を基盤とした独自サービスを構築する動きも今後広がりそうだ。
本記事は楽天グループ株式会社の公式プレスリリース(2026年3月17日付)およびHuggingFaceの公開情報をもとに構成しました。
https://corp.rakuten.co.jp/news/press/2026/0317_01.html
https://huggingface.co/Rakuten/RakutenAI-3.0
https://huggingface.co/Rakuten/RakutenAI-3.0/blob/main/NOTICE