1台のGPUに何十もの専門AIエージェントが同居する。しかもVRAM消費は増えない。それが、今研究者たちが本気で取り組んでいる課題だ。
マルチエージェントシステムの設計では、エージェントごとにモデルを用意するのが素朴なアプローチだ。コード生成担当、要件整理担当、レビュー担当……、コンテキストを共有したくない役割が増えるほど、GPUメモリの消費量は比例して膨らむ。倍々ゲームだ。
しかし実際の研究は、別の方向を向いている。パラメーターを共有したまま、複数のエージェントをうまく切り分け、効率よく動かすという方向だ。
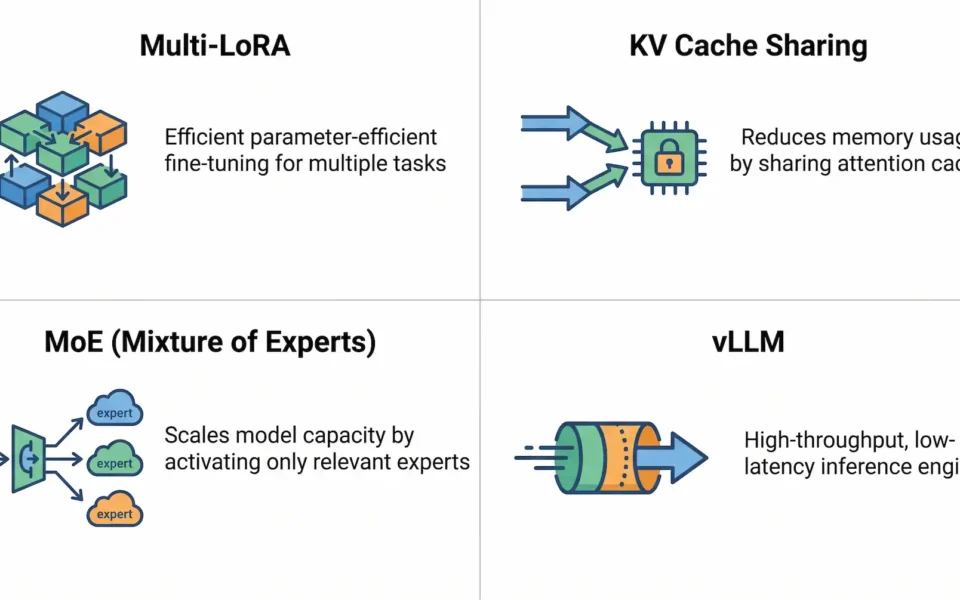
この記事では、その核心にある技術「Multi-LoRA」、「KVキャッシュ共有」、「統合推論エンジン」、「MoEアーキテクチャ」の最新動向をご紹介しよう。
まずトランスフォーマーとアテンションの話から
LLMの内部構造を理解するうえで避けられないのが、2017年に発表された「Attention Is All You Need」が提案したトランスフォーマーアーキテクチャだ。
従来のRNNは入力を順番に処理するため、長い文脈を扱うと情報が薄まりやすかった。トランスフォーマーはこれを「アテンション機構」で解決した。アテンションとは、文中の各トークンが他のすべてのトークンとどれだけ関連しているかを計算し、関係の強さに応じて情報を重み付けする仕組みだ。
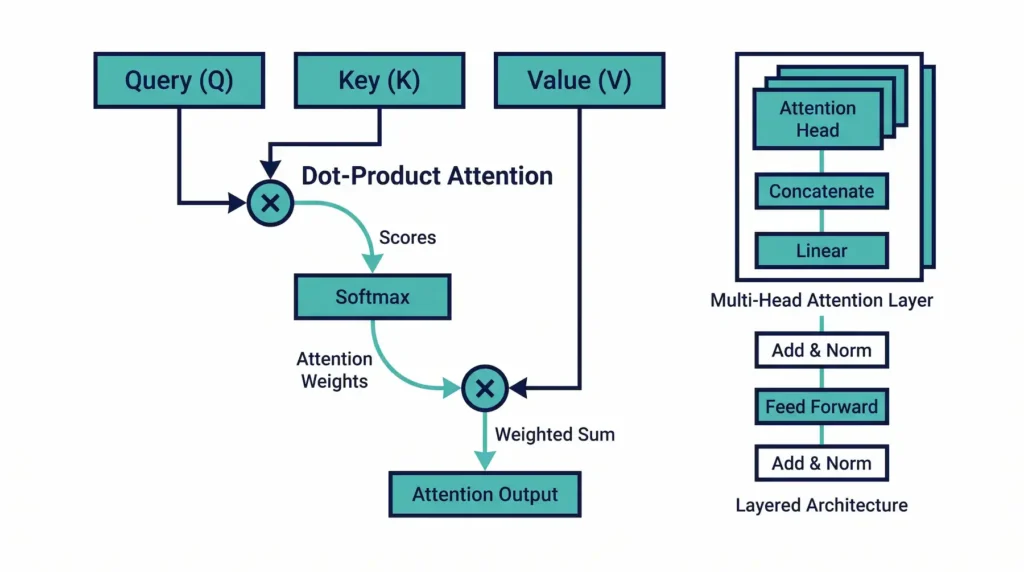
計算の中心にあるのは、Query(Q)、Key(K)、Value(V)の3つの行列だ。各トークンのQと全トークンのKの内積を取ってスコアを求め、そのスコアでVを加重平均する。これをすべての層で繰り返すことで、モデルは文脈を理解していく。
ここで重要なのが「KVキャッシュ」の存在だ。推論時、K行列とV行列は一度計算したら再利用できる。毎トークン生成のたびに全文脈を再計算するのは無駄なので、KVキャッシュとして保存しておくのが通常の実装だ。後述するKVキャッシュ共有の話は、この仕組みの延長線上にある。
Multi-LoRA:ベースモデルを共有したまま複数の役割をこなす
・LoRAとは何か
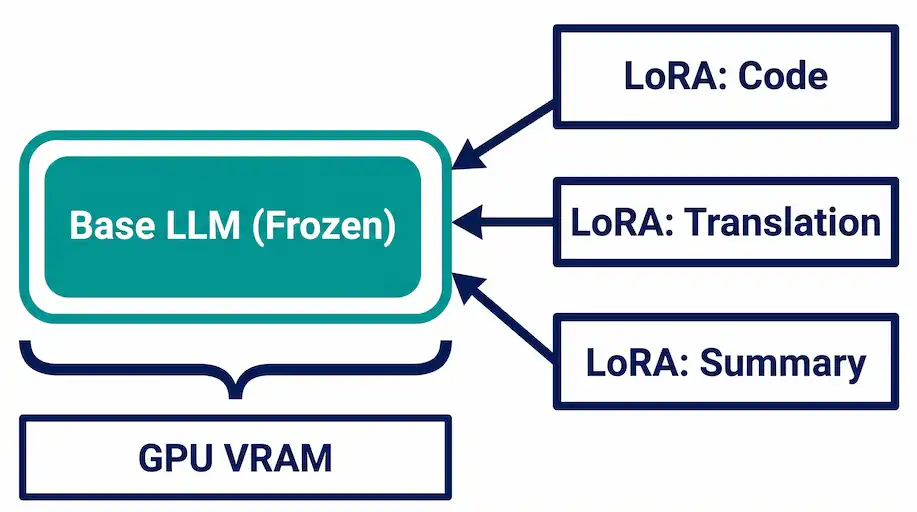
LLMをタスクに特化させる方法として広く使われているのがLoRA(Low-Rank Adaptation)だ。フルファインチューニングはモデル全体のパラメーターを更新するが、LoRAは本体を凍結したまま、各層に小さな低ランク行列(アダプター)を追加して学習する。必要なパラメーター数が大幅に減るため、学習コストとメモリが下がる。
LoRAアダプターはベースモデルとは別に保存される。推論時にアダプターをロードするだけで、そのタスクに適した挙動を引き出せる。
・Multi-LoRAが解く問題
では、LoRAアダプターが何十本もあるシステムではどうなるか。素朴な実装では、アダプターの切り替えのたびにGPUがモデル全体の重みをマージし直す。並列で複数のエージェントを動かすと、ベースモデルのコピーが台数分必要になる。これがメモリの無駄遣いの根本だ。
MLSys 2024で発表されたPunicaは、GPUクラスタで複数のLoRAモデルを共有サービングするシステムだ。専用のCUDAカーネル設計により、異なるLoRAモデルへのGPU演算をバッチ処理できる。これにより、GPUは複数の異なるLoRAモデルを提供する際に、元の事前学習済みモデルのコピーを1つだけ保持すればよくなった。評価では、当時の最高水準のLLMサービングシステムと比較して、複数LoRAモデルのサービングにおいて12倍のスループット向上を達成している。
S-LoRAはこのアプローチをさらに推し進め、1台のGPU上で何千ものLoRAアダプターをスケーラブルにサービングするシステムを提案した。すべてのアダプターをメインメモリに保存し、実行中のクエリで使用するアダプターだけをGPUメモリにフェッチする。動的なアダプター重みとKVキャッシュを統一メモリプールで管理するUnified Pagingという手法を採用し、HuggingFace PEFTやvLLMと比較してスループットを最大4倍改善した。
量子化との組み合わせも進んでいる。NeurIPS 2024で発表されたLoRA-Inlaidは、量子化された単一モデルを複数のLoRAアダプターで共有するアルゴリズムを設計し、モデルデプロイのメモリ消費を大幅に削減した。また、新しいタスクに対してLoRAアダプターをオンザフライで追加できるため、オンラインサービスの安定性を損なわない。スループットで最大1.58倍、平均レイテンシで最大1.76倍の改善を実現している。
VRAMへの貢献は明確だ。ベースモデルを1つだけGPUに置き、アダプターをホストメモリから動的にロードすることで、エージェント数が増えてもVRAM消費はほぼ横ばいを保てる。
KVキャッシュ共有:計算の重複を根本から減らす
・マルチエージェントでKVキャッシュが問題になる理由
複数のエージェントが協調して動くとき、コンテキストの大部分は重複している。
システムプロンプト、共有されたタスクの説明、これまでの会話履歴。
これらは各エージェントが独立して処理する。何も対策しなければ、同じテキストのKVキャッシュが台数分だけGPUに積み上がる。
マルチLLMエージェントシステムは、複数のエージェントが専門的な役割を担い、複雑なタスクを協調して分解・解決する能力により注目を集めている。長いトラジェクトリを扱うエージェントシステムでは、KVキャッシュのオーバーヘッドと計算負荷が単一エージェント設定よりも深刻になる。各エージェントが独自のKVキャッシュを維持し、コンテキストの大部分が共有されているにもかかわらず、冗長なプリフィルが発生するからだ。
・プレフィックスキャッシングとLMCache
共通するテキストプレフィックスのKVキャッシュを再利用する「プレフィックスキャッシング」は、vLLMでも実装されている基本的な最適化だ。しかし単一GPU内のメモリに収まる分しかキャッシュできないため、大規模なマルチエージェント環境ではすぐに限界が来る。
LMCACHEはvLLMやSGLangといった推論エンジンと組み合わせて動作するKVキャッシュ層だ。KVキャッシュをGPU、CPU、ストレージ、ネットワーク層にまたがって管理し、マルチラウンド質疑応答や文書分析などのワークロードでvLLMとの組み合わせにより最大15倍のスループット改善を示している。
このアプローチでは、KVキャッシュは単一GPUのメモリ容量に制約されなくなり、クラスタ全体からアクセス可能なスケーラブルな共有リソースになる。GPUは冗長なプリフィルに計算資源を費やす必要がなくなる。
・Multi-LoRAとKVキャッシュの組み合わせ問題
Multi-LoRAとKVキャッシュ共有を組み合わせると、別の問題が生じる。LoRAアダプターが異なると、同じ入力でも生成するKVキャッシュが変わるからだ。単純にキャッシュを共有すると精度が落ちる。
LRAgentはこの問題に取り組んだ研究だ。LoRAアーキテクチャのベースモデル部分のキャッシュと、低ランクアダプター部分のキャッシュを分離して管理するアプローチを採る。完全共有に近いメモリ・推論効率を実現しつつ、非共有ベースラインに近い精度を維持できる。
統合推論エンジン:vLLMとSGLang
複数エージェントのワークロードを実際に動かすには、これらの最適化をまとめて扱える推論エンジンが必要だ。
vLLMはPagedAttentionを提案した論文から生まれたオープンソースの推論フレームワークで、KVキャッシュをページ単位で管理することでメモリ断片化を減らし、高スループットを実現する。現在はMulti-LoRAサービングにも対応しており、S-LoRAやLMCacheとの統合も進んでいる。
SGLangはプログラマブルなLLM実行グラフを記述できる点が特徴で、複数ステップにわたるエージェントのワークロードを最適化しやすい。LMCacheはvLLMだけでなくSGLangとも統合されており、ページドアテンションメカニズムを採用する推論フレームワークであれば、統合は比較的容易だと報告されている。
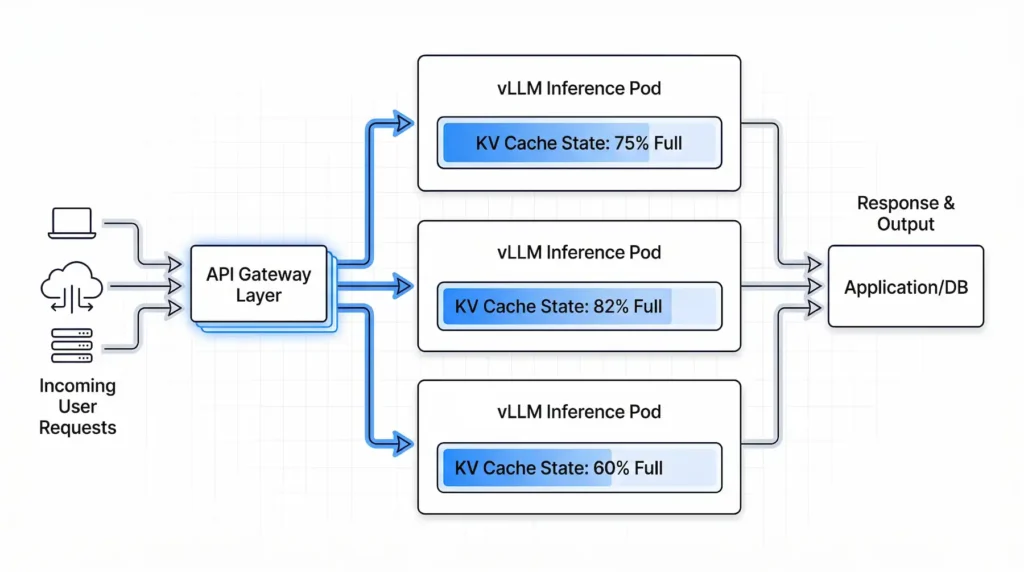
ルーティングレイヤーでのKVキャッシュ活用も進んでいる。llm-dは、ゲートウェイがキャッシュ状態を把握したうえでリクエストをスケジューリングするシステムだ。KVキャッシュブロックの一致度に基づいてリクエストを最適なpodにルーティングすることで、RAGやエージェントワークロードのような大きな共有コンテキストを持つ場面での高並列処理を改善する。
MoE:疎な活性化による構造的なVRAM削減
・アーキテクチャの仕組み
Mixture of Experts(MoE)は、FFN(フィードフォワード)層を複数の「エキスパート」サブネットワークに分割し、各トークンの処理には一部のエキスパートだけを使うアーキテクチャだ。ゲーティングネットワーク(ルーター)が入力を見て、どのエキスパートを使うかを動的に決定する。
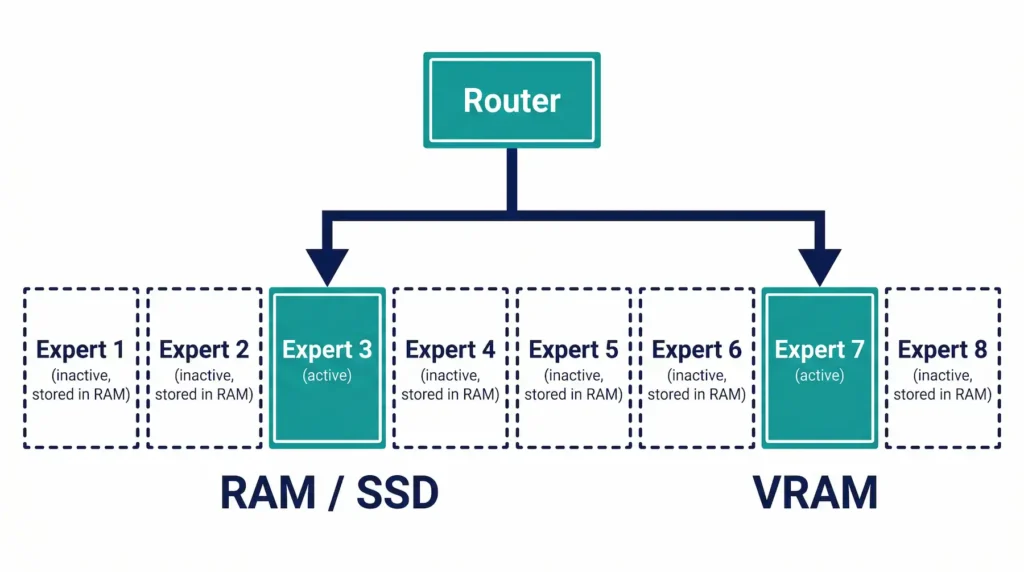
MoEは事前学習時に少ない計算量で済む一方、推論時はすべてのエキスパートをRAMにロードしておく必要があるためメモリ要件が高くなる。たとえばMixtral 8x7Bは一度に2つのエキスパートしか使わないが、全パラメーターは約47Bあり、それだけのVRAMが必要になる。
DeepSeek-R1を例に取ると、エキスパートパラメーターはモデル全体の97.45%を占めるが、1トークンあたりで実際に使われるのは3.13%にすぎない。この特性が、エキスパートをRAMやSSDにオフロードし、必要なものだけPCIe経由でVRAMにロードするオフローディング戦略を可能にしている。
・マルチエージェントとMoEの相性
MoEアーキテクチャはマルチエージェントシステムとも相性がいい。Kimi K2はトリリオンパラメーターのMoEモデルで、384のエキスパートとtop-8ルーティングを採用している。推論時に使われるのは全重みの約2%だ。このモデルはエージェンティックインテリジェンスに特化してチューニングされており、ツール使用や外部アクションを伴うマルチステップタスクに優れている。
複数の専門エージェントを構成する場合、MoEモデルのエキスパートが内部的な役割分担を担う形になる。個別のエージェントに個別のモデルを割り当てる代わりに、単一のMoEモデルが入力に応じて異なるエキスパートを動的に選択する。これにより、表向きは複数の専門家が協調しているように見えながら、VRAMの消費はベースモデル1つ分に抑えられる。
エキスパートのオフローディング研究も進んでいる。MoEpicは各エキスパートを上下2つのセグメントに縦断的に分割し、頻繁に使われるエキスパートの上位セグメントだけをVRAMにキャッシュする手法を提案した。実験ではGPUコストを約半分に削減しつつ、推論レイテンシをベースラインと比較して37.51%〜65.73%低下させている。
https://arxiv.org/abs/2509.08342v1
VRAMへの貢献をまとめると
技術ごとにVRAMへの貢献を整理すると、次のようになる。
Multi-LoRAは、エージェント数にかかわらずベースモデルのGPU上のコピーを1つに抑える。アダプター自体は軽量なのでホストメモリに多数保持でき、必要なものだけGPUに転送する。
KVキャッシュ共有は、複数エージェントが同じコンテキストを持つ場合の重複保存をなくす。LMCacheのようなソリューションはCPUメモリやストレージにキャッシュを階層化するため、GPU上のメモリを実際のトークン生成計算に集中させられる。
MoEは、モデルの総パラメーター数に対して推論時の計算量とメモリ帯域幅の使用量を大幅に減らす。エキスパートオフローディングとの組み合わせで、巨大なモデルが単一GPUで動く。
これらを統合するvLLM/SGLangは、上記の最適化を実際のサービングに組み込む実装基盤として機能する。
現時点での課題
技術的な課題は残っている。
KVキャッシュ共有はセキュリティリスクを伴う。共有されたKVキャッシュはタイミングサイドチャネルを生む。クエリを発行してTTFT(初回トークン生成までの時間)を測定することで、攻撃者はキャッシュヒットとミスを区別し、他のユーザーのプロンプトを推測できる。
この種の攻撃はブラックボックスAPIを通じて実行可能だ。マルチテナントのマルチエージェント環境では、キャッシュ共有とプライバシー保護のトレードオフを設計レベルで考える必要がある。
MoEのルーティングの安定性も引き続き研究されている。2025年中盤以降、技術的な焦点はパラメーター数の増加よりも、長い学習ラウンドとデプロイ制約のもとでルーティングを信頼できるものにすることへと移っている。
Multi-LoRAでは、量子化との組み合わせが従来は難しかった。主流の量子化手法はベースLLMのタスク間共有を妨げる場合があり、既存のLLMサービングシステムはLLM量子化と複数LoRAアダプターを統合してメモリ効率の高いマルチタスクサービングを実現することが困難だった。LoRA-Inlaidのような研究がこの壁を破り始めているが、フロンティアモデルの本番環境での実績はまだ積み上がっている途中だろう。
おわりに
「同じパラメーターで複数エージェントを効率的に動かす」という問いは、GPUの調達コストが現実の制約として効いてくる今、純粋な研究の話にとどまらない。Multi-LoRA、KVキャッシュ共有、MoEの組み合わせは、その答えの有力な候補として研究の中心にある。
2024〜2026年にかけて発表された成果を見ると、個々の技術は成熟期に入りつつある。ローカルLLMの性能は数年前に比べて格段に上がっている。それはモデルのパラメーターサイズよりはアーキテクチャの洗練による貢献が大きい。
次のフェーズは、これらを統合した実装が本番環境で動き続けることを証明する段階だろう。AIを動かすためのコストはどんどん下がりつつある。