Alibabaのチームが2026年4月、Qwen3.6-35B-A3Bをオープンウェイトモデルとして公開した。ライセンスはApache 2.0で、商用利用も改変も自由にできる。
このモデルの構造がちょっと変わっていて、パラメータ総数は35Bだが、推論時に実際に動くのは3Bだけ。スパースなMixture-of-Experts(MoE)アーキテクチャなので、フルサイズの35Bを常に動かすわけではない。つまり計算コストは3Bクラスに近いのに、35B分の知識は詰まっている、というのが魅力だ。
ローカルLLM界隈で人気だったQwen3.5-27Bと比べると
今年初め、ローカルLLMコミュニティでよく話題になっていたのがQwen3.5-27Bだった。今回出たモデルの前モデルであるQwen3.5-35B-A3Bよりも性能が良く、現実的な用途に使えるローカルLLMの有力な選択肢とされていた。
今回出されたMoEモデルのQwen3.6-35B-A3Bはそのライバルになりえる存在で、ベンチマーク上は27Bを上回る数字が並んでいる。コーディングエージェント系のタスクで差が顕著で、SWE-bench Verifiedでは73.4対75.0(27Bが若干上)だが、Terminal-Bench 2.0では51.5対41.6とかなり開きがある。SWE-bench Proは49.5対51.2と27Bがわずかに上回るものの、全体的なバランスでは27Bと十分に張り合える水準にある。
推論コストを考えると話が変わってくる。27Bの密モデルは常に27B分のパラメータを動かすが、35B-A3BはMoEなので実際の計算量は3Bに近い。同じハードウェアで動かすなら、スループットでは35B-A3Bのほうが有利になる場面も出てくる。
今回こそ、エコなMoEモデルがベンチマーク上では追い越した形だ。
MoEなのに数字が良い、という点について
MoEモデルは「パラメータ数は大きいが実際のコストは小さい」という設計で、以前はどこか性能面でトレードオフがあるイメージがあった。Qwen3.6はその印象をだいぶ塗り替えつつある。
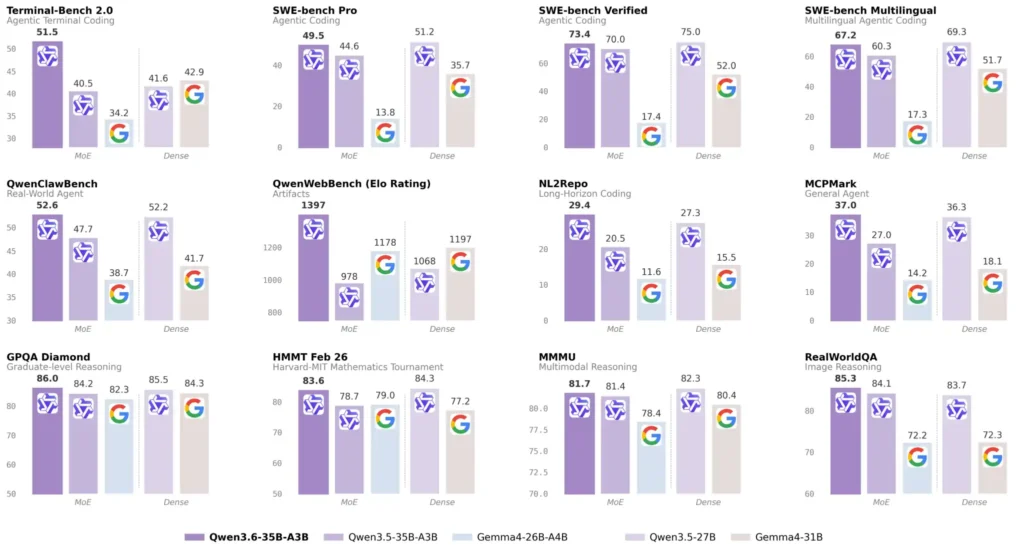
画像を見ると分かりやすいが、MoEカテゴリで比較されているGemma4-26B-A4Bとの差が各ベンチマークで相当大きい。SWE-bench Verifiedでは73.4対17.4、Terminal-Bench 2.0では51.5対34.2。GoogleのMoEは世代の違いもあるが、それにしてもここまで差がつくのは少し意外な結果だ。
ちなみにGPQA DiamondやHMMT Feb 26といった推論系・数学系のベンチマークでは、MoEとDense(Qwen3.5-27B)の差がかなり縮まる。コーディングエージェント系のタスクで差がつきやすく、純粋な知識・推論系では比較的フラットになる傾向がある。
短期間で前モデルに比べ、しっかり性能を上げてきた形だ。
マルチモーダルと「thinking」モード
Qwen3.6はネイティブにマルチモーダルで、テキスト・画像・動画を処理できる。さらにthinkingモードとnon-thinkingモードを切り替えられる設計になっており、前者はステップバイステップで考えてから答え、後者は直接返答する。
コンテキスト長はネイティブで262,144トークン、拡張すれば最大約100万トークンまで対応するとされている。
動かすには
OllamaやvLLM、SGLangに対応している。Ollamaだとollama pull qwen3.6:35b-a3bで取得できる。Q4_K_M量子化で約24GB。FP16フルだと70GB前後なのでH100 1枚に収まる計算だが、量子化版なら手元のゲーミングPCでも動くかもしれない。
4bit量子化モデルなら、32GBのRAMがあれば十分に展開させて動かせそうだ。
HuggingFaceのページとOllamaのライブラリページにはUnsloth製のGGUFも並んでいて、すでに86種類のクオンタイズ版が公開されている。コミュニティの動きは早い。人気なモデルになりそうな気がする。
https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF
プロジェクトの状況について少し
Qwenプロジェクトの顔だったJunyang Lin氏が2026年3月に退任し、オープンソースコミュニティでは「Alibabaの方針が変わるのでは」という懸念も出た。ただAlibabaはオープンソースへのコミットを継続すると表明しており、今回のリリースはその言葉通りだった、ということになる。少なくとも今のところは……。
HuggingFace上のQwenモデルは派生含めて20万種以上、ダウンロード数はQwen3-VL-2B-Instructだけで1800万を超えている。MetaのLlamaを派生モデル数で上回っているのは、中国発のモデルとしてはかなり異例の存在感だ。
MoEは微妙…と思いつつも、Qwen3.5-27Bが好きだった人には、一度試す価値はあると思う。