「オープンウェイトの最新AIがなぜあそこまで急速に進化できたのか?」
その疑問について、一つの回答が出た。Anthropicが公開した調査報告は、薄々「まぁそうだろうな」と思われていた事実を白日の下に晒した。
1,600万件超の不正アクセス──発覚した「不正な蒸留」とは?
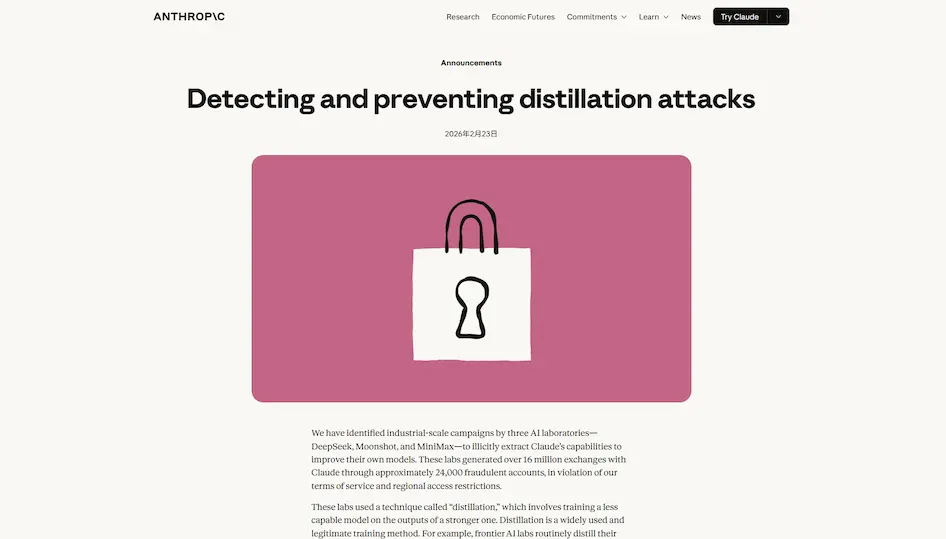
2026年2月23日、米AI企業Anthropicは驚くべき調査結果を公表した。中国のAIラボ3社──DeepSeek、Moonshot AI(Kimiモデル)、MiniMax──が、Anthropicの大規模言語モデル「Claude」から不正に能力を抽出しようとしていた、というものだ。
その規模は前例がない。約2万4,000件の不正アカウントを通じ、1,600万件以上のやり取りが生成された。これはサービス利用規約および地域ごとのアクセス制限に明確に違反する行為だ。
この行為の目的は「蒸留(Distillation)」と呼ばれる強力なモデルの出力を使って、より能力の低いモデルを訓練することである。「蒸留」それ自体は合法的な手法としてAI業界に広く普及している。比較的小さなAIモデルの性能を効率よく高める方法である。
問題は、競合他社のモデルに無断で適用する場合だ。独自に開発すれば何年もかかるような高度な能力を、コストと時間を大幅に節約しながら”盗み取る”ことができてしまう。
3社それぞれの手口
DeepSeek──15万件以上の不正アクセス
DeepSeekのオペレーションは、Claudeに「自分の回答に至るまでの内部推論を想像して、ステップごとに書き出せ」と指示するという巧妙な手法が特徴だ。これにより、強化学習用の思考連鎖(チェーン・オブ・ソート)データを大量生成していた。
さらに注目すべきは、政治的に敏感な質問(反体制派や党指導者に関する内容など)に対して**「検閲に引っかからない代替表現」を生成させていた**という事実だ。自社モデルを、こうした話題を巧みに回避するよう訓練する目的だったとAnthropicは分析している。
Moonshot AI──340万件以上の不正アクセス
Moonshootは数百の不正アカウントを複数の経路から使い分け、発覚を困難にする高度な手口をとった。ターゲットはエージェント型の推論・ツール使用・コーディング・コンピュータービジョンといったClaudeの最先端機能だ。リクエストのメタデータから、同社のシニアスタッフの公開プロフィールと一致する情報が確認されたという。
MiniMax──1,300万件以上の不正アクセス
3社の中で最大規模だったのがMiniMaxだ。Anthropicはキャンペーンが進行中の段階で検知することに成功し、データ収集からモデルリリースまでの全ライフサイクルを観察できた。
特筆すべきは、Anthropicが新モデルをリリースした際、MiniMaxが24時間以内にトラフィックの約半分を新モデルへ切り替えたという事実だ。最新モデルの能力を効率よく吸収するための素早い適応であり、攻撃の組織的かつ意図的な性質を如実に示している。
なぜこれが「国家安全保障上の問題」なのか
単なる知的財産の侵害にとどまらないのが、この問題の深刻さだ。
AnthropicをはじめとするAI企業は、生物兵器開発や悪意のあるサイバー攻撃への悪用を防ぐ安全対策をモデルに組み込んでいる。しかし不正に蒸留されたモデルは、こうした安全機能が失われている可能性が高い。
さらに蒸留攻撃は、AIに関する輸出規制を骨抜きにする効果も持つ。最先端チップのアクセス制限によって米国のAIリードを守ろうとしている中、蒸留攻撃を使えば高度な能力を間接的に”輸出”できてしまう。Anthropicは「中国系ラボの急速な進歩の一端は、この不正な能力抽出によるものだ」と指摘している。
Anthropicの対抗策と業界への呼びか
Anthropicは現在、以下の対策を進めていると明かした。
検知システムの強化として、蒸留攻撃パターンを識別する分類器や行動フィンガープリントシステムを構築。情報共有として、技術的指標を他のAIラボ・クラウドプロバイダー・関係当局と共有している。アクセス制御の厳格化では、不正アカウント開設に利用されやすい教育・研究向け申請の審査を強化。さらにカウンターメジャーとして、不正蒸留の有効性を低下させるモデルレベルの保護機能も開発中だという。
同社はこう呼びかける。「一社では解決できない。AI業界、クラウドプロバイダー、そして政策立案者が連携した、迅速かつ協調的な対応が必要だ」
巨額の投資で得られた成果が、不正に横流しされると、企業の収益問題にかかわる。


まとめ──AIの「進歩」はすべて実力なのか
今回の報告は、AIの急速な進化の裏にある「影の競争」を白日の下にさらした。蒸留攻撃は技術的に洗練され、規模も拡大し続けている。この問題が業界全体、そして安全保障の観点からどう対処されるかは、AI開発の未来を左右する重要な問いとなっている。
Anthropicは今回の不正を暴くと同時に、Responsible Scaling Policy(RSP)バージョン3.0を公開した。AI業界をリードする企業としての危機感が現れた形だ。
Anthropic単独で実施する対策と、AI業界全体で取り組むべき対策を明確に区別。
セキュリティ・アライメント・セーフガード・政策の4分野における具体的な目標を公開し、進捗を透明に評価。
3〜6ヶ月ごとにモデルの安全プロファイルを公開し、独立した第三者専門家によるレビューを実施。
高レベルのセキュリティ基準(例:モデルの重みを保護するSL5レベル)は「現時点では実現不可能」という研究結果から、国家安全保障コミュニティの支援が必要であろうとの言及を追加した。
以上の点で以前のRSPと異なっている。これから健全なAI開発競争は生まれるか?生成AI業界全体に注目していきたい。
出典:Anthropic公式発表「Detecting and preventing distillation attacks」(2026年2月23日)
https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks