人類は2000年かけて「専用計算機」から「汎用計算機」へと進化してきた。 だがいま、その流れが逆転している。 そして皮肉なことに、この逆転を起こしたのは、汎用コンピュータで解けない問題を解こうとした「AI」そのものだった。
少し専門的な話も入ってくるが、SF小説を読んでいる気分で読んでいただきたい。
専用から汎用へ、そして再び専用へ
・まず算盤から電卓へ、電卓から汎用機へ
紀元前の算盤から始まり、17世紀のパスカルの計算機、19世紀のバベッジの解析機関、人類の計算機の歴史は長い間、「特定の計算だけをこなす専用機」の歴史だった。
転機は20世紀半ば、ノイマン型アーキテクチャの登場だ。プログラムをメモリに格納し、汎用のCPUが何でも処理できる。この設計思想が、現代コンピュータの礎となった。その後は加速度的な汎用化の歴史だ。1チップに収まったCPU、インターネットにつながったPC、スマートフォン、クラウド。「1台のマシンがあれば文書作成も動画編集も会計処理も何でもできる」という世界を、人類は70年かけて作り上げた。
しかしそのトレンドは反転しつつある。

・「AIで何でもできる機械を作ろうとしたら、専用チップが必要になった」
興味深い逆説はここにある。
人類が「汎用コンピュータで解きにくい問題(自然言語処理、画像認識、翻訳、創造)をAIで解こう」と決意した瞬間、その夢を実現するために、圧倒的に「特化した」ハードウェアが優位になり始めたのだ。
AIが要求する計算は、フォン・ノイマン型汎用コンピュータが最も苦手とする種類のものだった。膨大な量の行列演算。数字の掛け算と足し算を、数十億回、同時並行に。これは汎用CPUが最も不得意とする作業だ。そしてGPUがある
こうして2015年、Googleのデータセンターにひっそりと設置されたのが「TPU(Tensor Processing Unit)」だった。人類が2000年かけて達成した「汎用化」を、あえて捨てた専用チップである。
TPUとは何か?「行列計算機」という驚くほどのシンプルさ
・ディープラーニングは「掛け算と足し算の塊」である
TPUを理解するには、まず「ニューラルネットワークが何をしているか」を知る必要がある。
驚くほど単純な話だ。ニューラルネットワークの各層は、本質的には「行列の掛け算」しかしていない。入力データ(数値の配列)を「重み(Weight)」という別の数値配列と掛け合わせ、その結果を次の層に渡す。この「掛け算→総和→次の層へ」というサイクルを、数百〜数千の層で繰り返す。それがGPT-4も、Geminiも、Claudeも、やっていることの本質だ。
数学的に書けば:出力 = 活性化関数(重み行列 × 入力ベクトル)
これだけだ。
当然、問題は「この行列の掛け算を何百億回も効率よくやれるか」に集約される。そしてCPUは、この特定の作業が苦手だった。CPUは「汎用性のために」複雑な機構(キャッシュ、分岐予測、アウトオブオーダー実行)を持ち、1命令ずつ順番に処理する設計だからだ。
・GPUという「偶然の英雄」
2010年代初頭、研究者たちは気づいた。「ゲーム用に作られたGPUが、なぜかディープラーニングに向いている」と。
GPUはもともと、3Dゲームの描画、つまり画面の何百万ピクセルを同時に計算するために作られた。そのために数千の小さな演算ユニットを並べて「並列処理」をする設計になっていた。そしてこの「大量並列処理」が、行列演算にも有効だった。偶然の産物だ。
しかしGPUは依然として「汎用」だ。レンダリングもAI計算も物理シミュレーションも何でもできる分、すべての計算でメモリへのアクセスが発生し、そのたびにエネルギーが消費される。
ニューラルネットワークは本質的に行列掛け算の連続であり、本当のボトルネックは計算そのものではなくメモリアクセスだ。このメモリのシャッフルが、演算自体の10〜100倍ものエネルギーを消費している。
Googleはここに着目した。
・「シストリックアレイ」1978年の古いアイデアが救世主になった
TPUの核心技術は「シストリックアレイ(Systolic Array)」と呼ばれる構造だ。実はこれ、1978年にH.T.カンとチャールズ・レイザーソンが提唱した、40年以上前のアイデアである。
「シストリック(Systolic)」は「収縮期の」という意味で、心臓の拍動から来ている。心臓が律動的に血液を押し出すように、データが処理ユニットの格子状配列を波のように流れていく……。これがシストリックアレイの動作原理だ。

TPUはGPUとは根本的に異なる設計で作られている。CPUは汎用性のためにレジスタに値を格納し、どのレジスタを読むか、どの演算をするか、結果をどこに書くかをプログラムが指示する構造だ。TPUのMXU(行列乗算ユニット)はこれとは全く違い、一度のクロックサイクルで数十万の演算を処理できる行列プロセッサとして設計されている。
具体的には以下のような動作だ。
TPUの動作手順(超簡潔に):
- 「重み(Weight)」データを格子状に並んだ演算ユニット(MAC: 掛け算と足し算をするだけの単純回路)に読み込む
- 入力データが左から右へ波のように流れていく
- 各MACは「掛けて、隣に渡す」だけ
- 結果が格子の端から出てくる
重みを一度読み込んで格子状のMAC全体に保持しておき、入力(活性化)データを左端から流す。各MACは保持している重みと流れてきた入力を掛けて、上から来た部分和に足し、両方を隣に渡す。この過程で、各重みは256回再利用され、各入力も256回再利用され、その間一切メモリにアクセスしない。これが圧倒的なエネルギー効率の源だ。
この巨大な行列掛け算の実行中、6万4000個のALU間で中間結果がメモリアクセスなしに直接受け渡しされ、消費電力が大幅に削減される。
・TPUとニューロンの類似、これは「偶然の一致」ではなく「論理的な必然」だ
ここで、少し立ち止まって考えてほしい。
なぜTPUが最適なのか。その問いへの答えは、驚くほどシンプルな論理の連鎖によって導き出される。

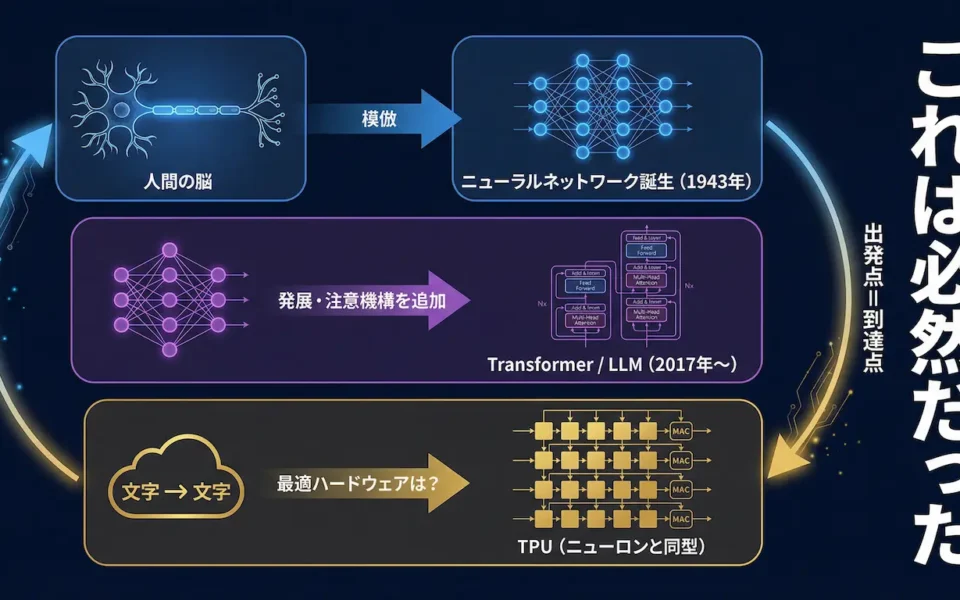
①:ニューラルネットワークは「人間の脳を模倣した」
1943年、神経科学者ウォーレン・マカロックと数学者ウォルター・ピッツが「人工ニューロン」のモデルを発表した。生物の神経細胞が「入力信号を受け取り、閾値を超えたら次のニューロンへ信号を送る」という動作を、数学的に模倣しようとしたのだ。
この出発点は重要だ。ニューラルネットワークはもともと、人間の脳を計算機で再現するという、極めて「人間中心」な動機で生まれた。
②:トランスフォーマーは、そのニューラルネットワークの上に構築された
2017年、Googleが発表した論文「Attention Is All You Need」は、現在のLLM(大規模言語モデル)の基盤となるトランスフォーマーアーキテクチャを世界に示した。
トランスフォーマーは、ニューラルネットワークの基本原理(多数の「ニューロン」が重み付きの信号を伝播する)を受け継ぎながら、「注意機構(Attention)」を加えることで、言語の文脈を捉える能力を飛躍的に高めた。GPT、Gemini、Claude、Llamaといった現代のLLMはすべて、このトランスフォーマーを基盤としている。
つまり、LLMとは「人間の脳の模倣」の上に「人間の言語理解の模倣」を重ねた構造物だ。
③:ならば、LLMを最も効率よく動かすハードウェアが「人間の脳に近い構造」になるのは、自明だ
「掛けて、隣に渡すだけ」——これがTPUの各処理ユニット(MAC)のすべてだ。
そしてこれは、脳のニューロンの動作と構造的に同型である。
| 脳のニューロン | TPUのMAC | |
|---|---|---|
| 入力 | 他のニューロンからの電気信号 | 左から流れてくる活性化データ |
| 重み | シナプスの結合強度 | 格子に保持されたシナプス係数 |
| 処理 | 荷重和の計算 | 掛け算+足し算(MAC演算) |
| 出力 | 次のニューロンへ信号を送る | 結果を隣のセルへ渡す |
| 局所性 | 隣接ニューロンとしか通信しない | 外部メモリアクセスなし |
この対応は比喩ではない。数学的に同型なのだ。
脳は「中央の巨大なメモリから情報を読み書きする」設計をしていない。各ニューロンは局所的に、隣接する細胞とだけ信号をやりとりする。そのため脳は、体重の2%の重さで体全体のエネルギーの20%を使うという高い効率を誇りながらも、気温が変わっても故障せず、数十年動き続けることができる。
TPUのシストリックアレイも、まったく同じ原理で設計されている。外部メモリへのアクセスを排除し、データは格子状のMACを「隣へ隣へ」と流れるだけ。これによりエネルギー効率が飛躍的に向上する。
人間を模倣するために作られたニューラルネットワーク、そのニューラルネットワークの考え方を元に発展したトランスフォーマー、そしてLLM。そのLLMを最も効率よく動かすハードウェアが、人間の神経回路に最も近い構造を持つ——これは「偶然の一致」でも「面白い比喩」でもなく、最初から決まっていた論理的な必然だ。
「ニューラルネットワーク(神経網)」という名称は、単なるマーケティング上の比喩ではなかった。人間の脳を模倣しようとした出発点が、最終的に「最適なハードウェアも人間の脳に近くなる」という結末を引き寄せたのだ。
・TPUが苦手なこと「行列計算機」であることの代償
TPUの設計哲学は徹底した特化だ。その代償として、TPUは多くのことを「できない」。
TPUはワードプロセッサを動かしたり、ロケットエンジンを制御したり、銀行トランザクションを処理したりできない。だができることは、ニューラルネットワークで使われる大規模な行列演算を高速で処理することだ。
分岐予測なし、キャッシュ管理なし、汎用命令セットなし。TPUv1の命令セットはたった12種類しかない。CPUが数百の命令を持つのと対照的だ。しかしこの「シンプルさ」こそが強さの源でもある。複雑なことをしないから、やるべきことに全エネルギーを集中できる。
この決定論的な実行モデルをキャッシュなし、分岐予測なし、アウトオブオーダー実行なしという特性により、GPUでは保証できなかったレイテンシの一貫性を実現している。
・GoogleのGeminiもTPUでトレーニングしている
Google TPUの実力を示す最大の証拠は、Google自身の使い方だ。
2024年に発表された「Gemini 1.5」は、その論文の中で「TPUv4およびTPUv5eクラスターで学習・推論を実施」と明記している。現行のGemini3.1、検索の裏側で動くAIアシスト、Google翻訳の深層学習エンジン……。これらすべてがTPU上でトレーニングされ、動いている。
そしてAnthropicは2025年10月、GoogleのTPUを最大100万枚利用する史上最大規模の契約を締結した。今あなたが読んでいるこの文章も、AIによる執筆支援を使用しているため、TPUインフラ上で処理されている可能性がある。興味深いことだろうと思う。
世代進化:「TPUが7年間でどれだけ変わったか」
| 世代 | 発表年 | 主な革新 | 演算能力 |
|---|---|---|---|
| TPU v1 | 2015 (内部) | 推論特化、シストリックアレイ | 92 TOPS |
| TPU v2 | 2017 | 学習対応、HBM採用 | 45 TFLOPS |
| TPU v3 | 2018 | 液冷、演算能力2倍 | 420 TFLOPS |
| TPU v4 | 2021 | 光通信スイッチ導入、ポッド構成 | 275 TFLOPS/chip |
| TPU v5e | 2023 | 推論効率最適化 | — |
| TPU v6 (Trillium) | 2024 | v5e比4.7倍高速、256chip/pod | — |
| TPU v7 (Ironwood) | 2025年4月 | 推論時代のためのTPU、9,216chip構成 | 4,614 TFLOPS/chip |
2025年4月のGoogle Cloud Nextカンファレンスで、GoogleはTPU v7「Ironwood」を発表した。このチップは256チップクラスターと9,216チップクラスターの2構成で提供され、ピーク演算性能は4,614 TFLOPS/sに達する。
「推論の時代のための最初のTPU」これがIronwoodに与えられたキャッチフレーズだ。AI開発が「学習(Training)」から「推論(Inference)」へ重心を移す中、Googleはアーキテクチャの哲学ごと転換した。
モデルをチップに焼くという究極の専用ハードも登場
TPUは「AI処理に最適化された専用チップ」だ。しかしここにきて、さらに先を行く発想が登場した。
モデルの重みそのものを、チップの配線として物理的に刻んでしまう。
詳しく別記事で解説しているので気になったら読んでみてほしい。

進む業界全体の「専用化」ラッシュ
TaalasとTPUは氷山の一角だ。テック各社が一斉に独自シリコンへと動き始めた。
- Amazon(AWS):Trainium2チップを大規模展開。Anthropicがモデル学習に採用
- Meta:MTIA(Meta Training and Inference Accelerator)を2026年から本格展開。独自のLlamaモデルに最適化
- OpenAI:Broadcomと協力し、2026年以降に独自ASICを開発予定
- Microsoft:Maia 100チップを展開中
- Apple:Neural Engineをすべての自社デバイスに搭載。推論をオンデバイスで完結
- Tesla:Dojo D1チップで自動運転モデルを学習
そして業界再編も急速だ。Groqの知的財産権をNvidiaが2025年末〜2026年初に約200億ドルで買収、GraphcoreはSoftBankが6億ドルで取得、SambaNova はIntelとの買収交渉が進む。

これは「退化」ではない!
「専用化への回帰」は、技術の後退ではないか—?この問いに答えておく必要がある。
答えは明確にノーだ。
1970〜80年代のDSP(デジタル信号処理)チップをご存じだろうか。電話の音声処理、レーダー信号の解析。これらに特化した専用チップが重宝された。その後CPUとGPUの汎用化が進み、SoCなどのパッケージング技術が向上し、専用チップの多くは市場から消えた。しかし現在起きていることは、あの時代への単純な回帰ではない。
規模が桁違いだ。TPU v7のクラスターは1台で42.5エクサフロップスに達する。「専用」であることの意味が根本的に変わっている。
AIが「インフラ」になったからこそ、最適化の深化が起きている。電力網が特定の電圧・周波数に「専用化」されているように、AIインフラもまた、最も多く使われるモデルに合わせて専用化されていく。これは普及期に入ったすべての技術に共通するパターンだ。
「汎用問題解決機」としてのAIと「それを動かすハード」は分離し始めている。AIがソフトウェアの層で「汎用性」を担い、ハードウェアはそのAIを最高効率で動かすことに特化する。この役割分担こそが成熟した技術の姿だ。
「モデルがコンピュータになる日」のインフラ
TPUが示した「行列演算への特化」という潮流は、Google、Amazon、Meta、Appleという世界最大のテック企業すべてが同じ方向に走っていることで裏付けられている。
振り返れば、シストリックアレイは1978年の古いアイデアだった。「掛けて、隣に渡す」という単純な動作が、2025年の最先端AIを動かしている。そしてそれは、ニューロンが神経伝達物質を隣の細胞に伝えるという、数億年の進化が作り出した最適解と、同じ原理を持っている。この技術の変容は、壮大なSF小説の様なある種の美しさと面白さがある。
コンピュータが「専用機」に戻ることは、退化ではない。それはAIが人間の知的活動に深く組み込まれる過程で、必然的に起きる最適化の結果だ。
2000年の歴史を経て、人類はまた新しい種類の「専用機」を作った。ただし今度は、人間の知性そのものを模倣するために。ただそれだけの話なのだ。