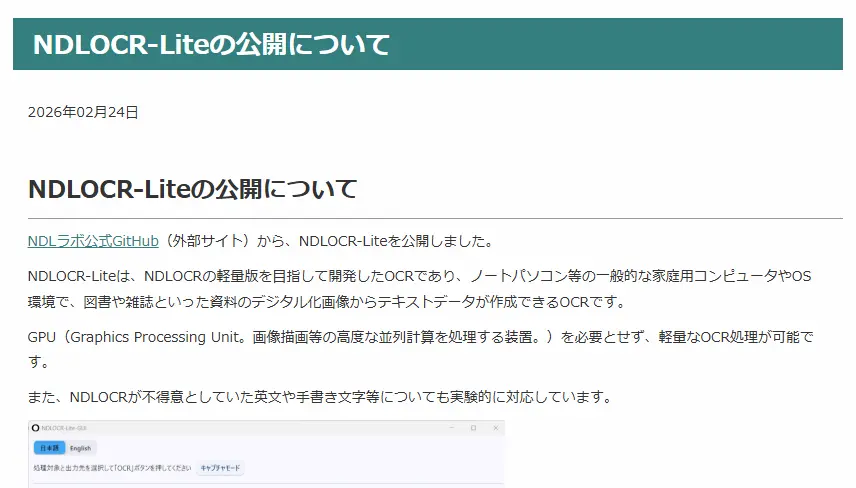
国立国会図書館(NDL)は、図書や雑誌などのデジタル化画像からテキストデータを作成できるOCRアプリケーション「NDLOCR-Lite」を公開しました。本記事では、同アプリケーションの主な特徴と、商用利用の可否について解説します。
https://github.com/ndl-lab/ndlocr-lite
NDLOCR-Liteの主な特徴
NDLOCR-Liteは、これまで提供されていた「NDLOCR」の軽量版として位置づけられており、以下の特徴を備えています。
- 動作環境の緩和:GPU(画像描画等の高度な並列計算を処理する装置)を必要とせず、ノートパソコン等の一般的な家庭用コンピュータで高速なOCR処理が可能です。
- 直感的な操作性:デスクトップアプリケーションが用意されており、コマンド入力を行わずマウス操作のみでテキスト化を実行できます。
- 幅広いOSに対応:Windows(Windows 11)、Mac(Apple M4, macOS Sequoia)、Linux(Ubuntu 22.04)の各OS環境で動作が確認されています。
- 適用範囲の拡大:NDLOCRが不得意としていた英文や手書き文字についても、実験的に対応しています。
商用利用は可能なのか?
ライセンスを確認した限り、NDLOCR-Liteを利用した商用利用は可能です。
国立国会図書館は、本アプリケーションを「CC BY 4.0(クリエイティブ・コモンズ 表示 4.0 国際)」ライセンスで公開しています。このライセンスは、適切なクレジット(国立国会図書館の名称、元のURLやライセンスへのリンクなど)を表示することを条件として、営利目的での利用、改変、再配布を許可するものです。
したがって、規定のクレジット表記を行うことで、本ソフトウェアで作成したテキストデータを自社の商用サービスに組み込んだり、業務に活用したりすることが認められています。
ただし、本アプリケーション自体を別のソフトウェアに組み込んで再配布や販売を行う場合は、内部で使用されている各種外部ライブラリ(Apache License 2.0、MIT License、BSD Licenseなど)が定める個別のライセンス条項にも従う必要がある点に留意が必要です。
利用時の留意点
- 古典籍資料の取り扱いくずし字や漢籍の資料も読み取れる場合がありますが、これらの資料に対して本格的なテキスト化を行う場合は、より読み取り精度の高い「NDL古典籍OCR」や「NDL古典籍OCR-Lite」の利用が推奨されています。
- 従来版の継続提供GPU環境を利用した処理を必要とする用途向けに、従来のNDLOCRも引き続き提供されています。
ダウンロードと詳細情報
最新版のアプリケーションや詳しい利用手順については、以下の公式リンクから確認できます。
- アプリケーションのダウンロード(リリースページ)https://github.com/ndl-lab/ndlocr-lite/releases
- NDLOCR-Liteの使い方https://lab.ndl.go.jp/data_set/ndlocrlite-usage/
- GitHubリポジトリ(従来版の案内含む)https://github.com/ndl-lab/ndlocr-litehttps://github.com/ndl-lab/ndlocr_cli