4倍高速なテキスト生成を狙う、Gemma 4ベースの拡散型オープンモデル
Google DeepMindは2026年6月10日、テキスト生成に拡散モデルの考え方を取り入れた実験的オープンモデル「DiffusionGemma」を発表した。DiffusionGemmaは、従来の大規模言語モデルのように左から右へ1トークンずつ文章を生成するのではなく、複数トークンからなるテキストブロックを同時に生成・修正していく点が最大の特徴だ。Googleは、専用GPU上で最大4倍の高速なテキスト生成を実現すると説明している。
DiffusionGemmaはGemma 4ファミリーとGemini Diffusionの研究を土台にしたモデルで、26B規模のMixture of Experts(MoE)アーキテクチャを採用する。総パラメータ数は約25.2B〜26B、推論時に有効化されるパラメータは3.8Bで、GoogleやNVIDIAは量子化時に18GB級のVRAMで動作可能だとしている。
ライセンスはApache 2.0で、Hugging Faceでも「google/diffusiongemma-26B-A4B-it」として公開されている。Hugging Faceのモデルページでは、Transformers、vLLM、SGLangなどからの利用例が示されており、研究者や開発者がローカル推論や独自アプリケーションへの組み込みを試しやすい形で提供されている。
自己回帰型ではなく「ブロックを磨く」生成方式
現在主流のLLMは、自己回帰型と呼ばれる方式でテキストを生成する。つまり、直前までに生成した文脈をもとに次の1トークンを予測し、そのトークンを追加して、また次を予測する。この仕組みは自然な文章生成に強い一方、生成は基本的に逐次処理になり、ローカルGPUでは計算能力は持て余す一方、メモリ帯域がボトルネックになりやすい。
DiffusionGemmaはこの流れを変える。Google Developers Blogによれば、DiffusionGemmaは「Uniform State Diffusion」と呼ばれる方式で、ランダムなプレースホルダトークンからなる256トークンの“キャンバス”を用意し、それを複数回のデノイジング処理で並列に洗練していく。高信頼度のトークンが周辺の推定を助け、最終的にテキストブロック全体が文章として収束する仕組みだ。
簡単な例で例えると、『タイプライターでの出力から、数回の操作で一気に文字を打てる印刷機に変わった』と言えるだろう。
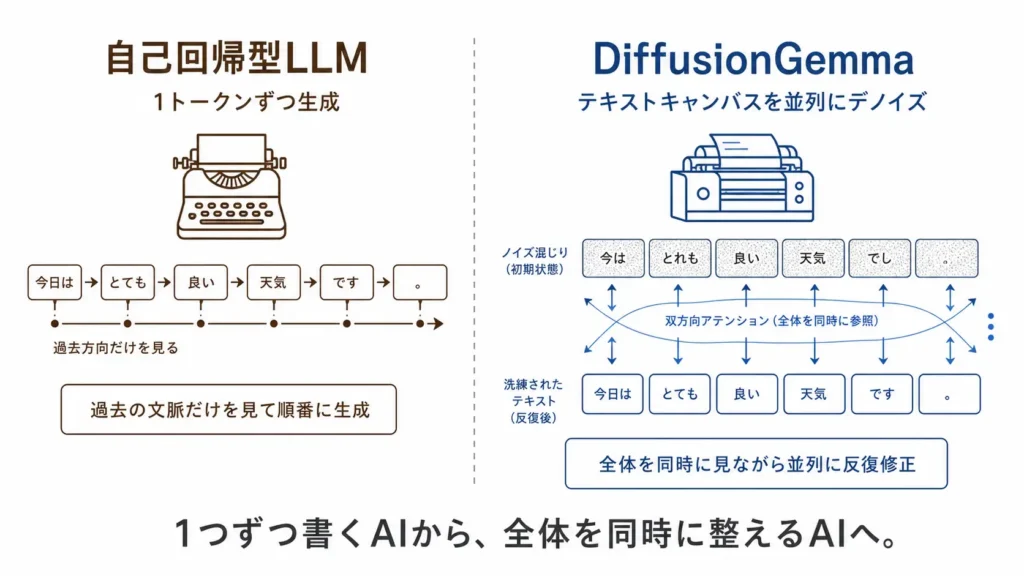
256トークンを超える長い出力では、1つのキャンバスが確定するとKVキャッシュにコミットされ、次の256トークンキャンバスへ進む。Hugging Faceの説明では、この方式は「block-autoregressive」と表現されており、ブロック単位の並列生成と、長文生成に必要な逐次的安定性を組み合わせる設計になっている。
なぜ速いのか:メモリ帯域から計算資源へ
DiffusionGemmaの高速化の鍵は、GPUの使い方にある。自己回帰型LLMでは、1トークン生成するたびにモデル重みを参照するため、処理がメモリ帯域に縛られやすい。Googleは、DiffusionGemmaが256トークンのキャンバスを並列に処理することで、ボトルネックをメモリ帯域から計算資源へ移し、Tensor CoreのようなGPUの演算能力をより活用できると説明している。
公称性能はかなり強気だ。Googleは、NVIDIA H100単体で毎秒1,000トークン以上、GeForce RTX 5090で毎秒700トークン以上を示している。NVIDIAも、H100で毎秒1,000トークン、DGX Sparkで毎秒150トークン、DGX Stationで最大毎秒2,000トークンといった性能値を紹介し、同等の自己回帰型モデルに対しておおむね4倍高速だとしている。
またGoogle DeepMindのモデルページでは、NVIDIAの新しいNVFP4、つまり4ビット浮動小数点形式へのネイティブ対応により、Blackwell世代GPUで高速化と精度維持の両立を狙うと説明されている。これは、DiffusionGemmaが単なるアルゴリズム上の実験ではなく、NVIDIA GPUエコシステムと強く結びついたローカルAI向けモデルとしても設計されていることを示している。
得意分野は「左から順番に書かない」タスク
DiffusionGemmaが狙うのは、すべてのLLM用途を置き換えることではないそうだ。Googleは、DiffusionGemmaを「速度重視のインタラクティブなローカルワークフロー」に向けた実験的モデルと位置づけており、標準的なGemma 4の自己回帰モデルは高品質な本番出力の標準であり続けるとしている。
特に相性がよいとされるのは、インライン編集、コード補完、コードの穴埋め、アミノ酸配列、数学的グラフ、構造化テキスト生成など、出力全体の整合性を見ながら生成・修正したい用途だ。DiffusionGemmaはブロック内の各トークンが双方向に他のトークンを参照できるため、未来のトークン情報を使えない通常の自己回帰型モデルとは異なる強みを持つ。
Google Developers Blogでは、数独を例にDiffusionGemmaの性質を説明している。数独では各マスが行・列・ブロック全体の制約を満たす必要があり、左上から順番に数字を確定する自己回帰型モデルには不利な構造を持つ。DiffusionGemmaはキャンバス全体を同時に評価・修正できるため、このような多変数制約を持つ問題で利点が出やすい。
マルチモーダル、長文、関数呼び出しにも対応
NVIDIA NIMのモデルカードによれば、DiffusionGemma 26B A4B ITは、テキスト、画像、動画を入力として受け取り、テキストを出力するマルチモーダル生成モデルだ。入力コンテキスト長は256Kトークンで、構成可能なthinking、ネイティブ関数呼び出し、35以上の言語での多言語推論にも対応するとされている。
画像入力については、可変アスペクト比・解像度に対応し、画像ごとの視覚トークン予算を70、140、280、560、1120トークンから設定できるとNVIDIA NIMは説明している。動画入力は最大60秒、1秒1フレームのフレーム列として処理される。
Hugging Faceのドキュメントでは、DiffusionGemmaは通常のTransformersモデルと同様にgenerate()インターフェースで扱える一方、内部では専用の拡散サンプリングループを持つと説明されている。また、一般的な自己回帰モデルと異なり、最終テキストだけでなく途中の“ドラフト”をストリーミング表示できる点も特徴だ。
制約:速いが、品質ではGemma 4に劣る
重要なのは、DiffusionGemmaが「より賢いGemma 4」ではないという点だ。Google自身が、DiffusionGemmaは速度と並列レイアウト生成を優先しているため、全体的な出力品質は標準のGemma 4より低いと明記している。最大品質が必要なアプリケーションでは、Googleは通常のGemma 4を推奨している。
このトレードオフは、テキスト生成に拡散モデルを使う難しさを反映している。画像生成ではピクセル単位の誤差が多少あっても全体として成立することが多いが、テキストは離散的で、1語や1記号の誤りが文全体、コード、JSON、数式の意味を壊すことがある。テキスト拡散は高速化の可能性を持つ一方、言語の離散性ゆえに誤りの影響が大きいと指摘している。
したがって、DiffusionGemmaの現実的な使いどころは、最終回答の完全性よりも低遅延・試行回数・インタラクション速度が価値になる領域だ。たとえばエディタ内補完、社内文書の下書き、ローカルAIアシスタント、エージェントの高速な中間思考、構造化テキストのたたき台生成などでは、多少の品質差を人間や後段モデルで補える可能性がある。
ローカルAIのUXが劇的に変わる可能性には期待してよさそう
DiffusionGemmaのインパクトは、単に「毎秒トークン数が増える」ことにとどまらない。ローカルAIで最も体感しやすい不満は、返答が“タイプされる”ように少しずつ表示される待ち時間だ。DiffusionGemmaのようにブロック単位で生成できるモデルは、コードエディタ、チャットUI、ドキュメント編集、エージェント実行ログなどのUXを変える可能性がある。
NVIDIAは、DiffusionGemmaがRTX PRO、DGX Spark、GeForce RTX GPU向けに最適化され、ローカルPCからクラウドまで動作すると説明している。クラウドAPIに依存せず、ローカルで高速な推論を行えることは、コスト、プライバシー、オフライン利用、社内データ処理の観点で開発者や企業にとって魅力的だ。
一方で、クラウドの大量同時処理環境では自己回帰型モデルのバッチ処理最適化が依然として強い場面もある。DiffusionGemmaは現時点では、幅広い本番LLM基盤を置き換えるというより、単一ユーザーの低遅延ワークロードや、ローカルGPUを使ったインタラクティブ用途で真価を発揮するモデルと見るべきだ。
ローカルで高性能なAIモデル並みのコード補完支援を受けられるようになる可能性は十分にあるだろう。
まとめ:DiffusionGemmaは「次世代LLM」ではなく「別解」に近い
DiffusionGemmaは、LLMの主流である自己回帰型生成に対する明確な別解を提示した。256トークンのキャンバスを並列に生成・修正する設計、双方向アテンション、MoEによる軽量な有効パラメータ、NVIDIA GPU向け最適化により、ローカル環境での高速テキスト生成という課題に正面から取り組んでいる。
ただし、現時点のDiffusionGemmaは実験的モデルであり、Google自身も品質面では標準Gemma 4に劣ると認めている。したがって、企業や開発者が採用を検討する際は、「最高品質の回答を出すモデル」ではなく、「低遅延で何度も試せる生成エンジン」として評価するのが妥当だ。
それでも、DiffusionGemmaの登場は重要だ。画像生成で拡散モデルが表現力と生成プロセスを大きく変えたように、テキスト生成でも“左から順番に書く”以外のアーキテクチャが実用圏に入り始めたことを示している。DiffusionGemmaは、LLMの未来が単一の生成方式に収束するのではなく、用途ごとに自己回帰型、拡散型、投機的デコード、MoE、オンデバイスモデルが使い分けられる時代へ向かうことを示す、興味深いマイルストーンだろう。