国立情報学研究所(NII)の大規模言語モデル研究開発センター(LLMC)が、新たな国産LLM「LLM-jp-4 8Bモデル」と「LLM-jp-4 32B-A3Bモデル」をオープンソースライセンスで公開した。
約12兆トークンのコーパスでフルスクラッチ学習したこのモデル、日本語ベンチマークではGPT-4oを上回るスコアを出している。
「フルスクラッチ」という点は、このプロジェクトの性格を考えると重要だ。
既存モデルのファインチューニングではなく、ゼロから学習を行っており、学習データも第三者が入手可能なソースに限定している。オープンソースAIの定義(OSAID)に沿って、データの透明性を担保した形で構築されている。「誰でも再現できる」ことを意識した設計で、国産LLMの研究基盤として使えるモデルを目指している。
モデルの詳細
モデルの詳細を見ると、8BモデルはLlama 2ベースで約86億パラメータ。32B-A3BモデルはQwen3 MoE(Mixture of Experts)ベースで総パラメータ数は約320億だが、推論時にアクティブになるのは約38億パラメータ分(8エキスパート)というアーキテクチャ構成だ。最大約6万5千トークンまで処理できる。
学習データの規模は前世代「LLM-jp-3.1」シリーズの約6倍。事前学習コーパスは総計約19.5兆トークンで、日本語約7,000億、英語約17.8兆、中国語・韓国語約8,500億、プログラムコード約2,000億トークンで構成されている。このうち実際に事前学習に使ったのは約10.5兆トークン。その後、合成データを加えた1.2兆トークンで中間学習も実施している。
気になる性能
ベンチマーク結果が興味深い。日本語理解を測る「日本語MT-Bench」では、8Bモデルが7.54、32B-A3Bモデルが7.82を記録。GPT-4oの7.29、Qwen3-8Bの7.14をいずれも上回っている。英語のMT-Benchでも8Bモデルが7.79、32B-A3Bモデルが7.86で、GPT-4oの7.69と同等以上だ。パラメータ規模を考えると、なかなか効率のいい結果といえる。
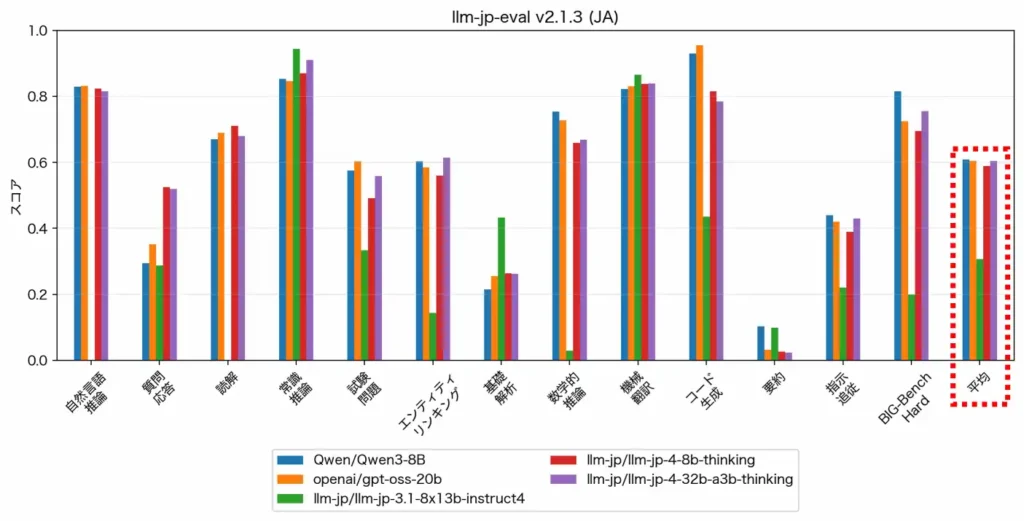
ただし、評価にGPT-5.4をジャッジとして使っているなど、LLM-as-a-Judge手法(モデルの出力品質を人間ではなく別のLLMに採点させる評価手法)特有の留意点はある。42種類の評価データを使う「llm-jp-eval v2.1.3」でも検証しており、日本語性能でQwen3-8Bと同等と確認されている。
LLM-jpは、NIIが主宰するLLM研究開発コミュニティで、大学・企業などから2,600名以上が参加している。早稲田大学、東北大学、東京大学、東京科学大学、名古屋大学など複数の大学の教授陣が各ワーキンググループを率いる、わりと大規模な産学連携の取り組みだ。学習にはAIST(産業技術総合研究所)のABCI 3.0を使用。コーパス面では国立国語研究所や国立国会図書館からも協力を得ている。
今後はより大規模な「LLM-jp-4 32Bモデル」と「LLM-jp-4 332B-A31Bモデル」を2026年度中に公開予定。軽量モデルの開発も並行して進めるとしている。
モデルやツール、コーパスの詳細は https://llm-jp.nii.ac.jp/release で公開されている。